Статья в сборнике
Юность. Наука. Культура: Материалы XI региональной открытой научно-практической конференции учащихся и студентов Вологодской области / Под обще ред. к. пед. н., доц. А. А. Огаркова – Вологда: ВРО ОДОО «МАН «Интеллект будущего», 2012. – С. 16-22.
Интернет представляет собой хранилище информации, не сопоставимое по масштабам не только с любым самым крупным аналогичным хранилищем на традиционных, неэлектронных носителях (в оффлайне), но и вообще со всей совокупностью таких информационных массивов в истории цивилизации. По данным Netcraft, компании, проводящей исследования в области Интернета, количество сайтов в глобальной сети к октябрю 2011 года достигло полумиллиардной отметки [1]. Тогда же, кстати, численность населения планеты превысила очередной порог – семь миллиардов человек. То есть, один сайт приходится в наше время на каждых 14 жителей планеты. Даже если учесть, что из 500 миллионов сайтов только 151 миллион (по данным того же исследования) – активных, реально действующих, всё равно получается весьма впечатляющая картина: один сайт на 46 человек, включая не только все социально-демографические группы и слои общества, но и целиком такие страны и территории, где Интернет отсутствует, как таковой, по разным причинам – техническим, экономическим, политическим, социокультурным… Это соотношение представляется нам настолько красноречивым, что не нуждается, на наш взгляд, в каких-либо комментариях.
Мы не случайно для количественных иллюстраций выбрали здесь такую, казалось бы, странную единицу измерения Интернета – сайт. В сущности, любой сайт представляет собой документ или совокупность документов, то есть, потенциальный источник информации, а именно с этой точки зрения Интернет и интересует нас в контексте настоящего исследования.
С одной стороны, чем больше информации, тем больше возможность выбора, сопоставления различных фактов и источников и получения объективной картины. С другой, как это ни парадоксально, то многообразие, о котором мы сказали выше, не упрощает выбор, а существенно усложняет его. Информации слишком много. Её настолько много, что очень трудно найти нужную и ещё труднее использовать её.
Здесь, однако, следует сделать три важнейших оговорки. Первая касается самого понятия информации, так, как оно используется в данном исследовании. Мы опустим здесь введённый К. Шенноном [2] такой фактор повышения энтропии символов, как шум. Иными словами, мы оставляем пока в стороне меру достоверности, и, следовательно, рассматриваем в качестве информации (по определению) всякую, которую сам разместивший её в Интернете человек полагает таковой.
Вторая оговорка связана с авторством, с проблемой субъекта продуцирования и распространения информации. Достоверность информации, о которой мы ведём речь в данной работе, теснейшим образом связана с тем человеком или теми людьми, которые берут на себя как юридическую, так и моральную ответственность за её публикацию и за соответствие действительности её содержания. В частности, автор отвечает за свой текст – репутацией. Это обязательное условие, следовательно, предполагается вообще её наличие у автора.
Третья оговорка ограничивает характер и целевое назначение информации. Это использование неких данных во всех видах исследований: учебных, учебно-научных, научных. А не любое потребление информации вообще. В рамках такой дисциплины, как маркетинг, информацию этого типа принято называть вторичной (в отличие от первичной, полученной исследователем непосредственно, например, в результате обработки данных опроса). Информацию в такой трактовке термина можно рассматривать, как универсальный, необходимый, хотя и не достаточный ресурс для любой исследовательской деятельности.
Если вернуться к статистике, упомянутой в начале настоящей статьи, получается, что научное и образовательное сообщество всего мира имеет сегодня «в лице» Интернета фантастический по своим масштабам ресурс для осуществления своей деятельности. Однако, данное обстоятельство не только стимулирует развитие образования и науки, но и, напротив, оказывает на эти области разрушительное воздействие. Причём, воздействие мощнейшее, сокрушительное по своей силе, способное нанести как науке, так и образованию, колоссальный и непоправимый ущерб. И дело не только в информации, которая не поддаётся проверке, но и в ряде других явлений. Эти явления, однако, оказываются предметом уже не теории информации, а таких наук, как социология, филология, психология, педагогика и маркетинг.
В слове достоверный этимологически читается достойный веры, и такое значение слова вполне приемлемо, когда мы говорим о качестве информации. В самой же проблеме достоверности, применительно к сведениям обсуждаемого здесь характера, мы выделяем два пересекающихся друг с другом аспекта: качества собственно информации и честности её получения и трансляции.
Качество самой информации зачастую трудно верифицировать из-за её обилия, для проверки нужна высочайшая квалификация. В обозримом будущем, с совершенствованием онлайн-переводчиков, потребуется ещё и приличное знание иностранных языков. Как определить, насколько соответствуют действительности те или иные статистические данные, насколько апробирован или корректен тот или иной тезис? Требования к квалификации исследователя в этом смысле возрастают чуть ли не пропорционально скорости роста количества информации в Интернете (а эта скорость очень велика).
Проверка качества информации из интернет-источников затруднена также из-за того, что сегодня очень легко стать автором, чрезвычайно прост и не сопряжён с трудовыми и финансовыми затратами процесс публикации любых материалов в Интернете. В силу данной причины в Интернете, наряду с вполне качественными текстами серьёзных исследователей, можно встретить невероятное количество творений самозванцев и псевдоучёных всех видов. Другой аспект проблемы состоит в расцвете плагиата, и даже не просто в расцвете, а фактически в его легализации, в превращении его изготовления в легально продаваемую услугу. Разумеется, научный (в формальном смысле) текст, авторство которого сфальсифицировано подобным образом, не может считаться в полной мере заслуживающим доверия. Кроме того, он в большинстве случаев даже не идентифицируется в качестве плагиата и выдаётся за диссертацию, вроде бы отвечающую всем требованиям качества.
Строго говоря, образование и науку разрушает следующее. Источники некачественной информации продуцируются в массовых количествах, они не могут быть тщательно проверены и поэтому используются и тиражируются без должной верификации, причём, сам факт тиражирования порой заменяет какую-либо апробацию: если опубликовано – значит, заслуживает доверия. Кроме того, работает и параллельная тенденция, ещё более губительная: студент загружает из Интернета и сдаёт, выдавая за собственный, реферат (содержательная и смысловая ценность которого, к тому же, стремится к нулю; это результат предыдущей обсуждаемой здесь тенденции), затем он так же «выполняет» курсовой проект, дипломную работу, в результате общество получает специалиста, качество знаний которого с необходимостью соответствует качеству потребляемых им информационных источников и честности работы с ними. То есть, качество полученного высшего образования существенно уступает среднему советского периода, всё, что умеет такой специалист – искать тексты в Интернете и бездумно копировать их. Казалось бы, этому может своевременно помешать преподаватель, но где гарантия, что сам он учился не точно таким же образом? Более того, не только учился, но и «писал» диссертацию: заказал её через соответствующий сайт, заплатил деньги, а возможно, и дал необходимые взятки, в результате получил диплом о присвоении учёной степени кандидата, а то и доктора наук.
Количественные параметры данной тенденции сейчас практически не поддаются прямому учёту, однако, косвенно о масштабах проблемы свидетельствует несколько фактов. Случаи разоблачения фальшивых кандидатов и докторов наук носят сегодня единичный характер, однако, предложение на рынке такого рода услуг продолжает расти, что немыслимо без соответствующего спроса и прибылей, а значит, без реально совершаемых актов купли-продажи. Вместе с тем, столь же единичный характер они носили ещё задолго до эпохи Интернета, см. об этом комедию С. Михалкова «Пена» [3], написанную ещё в 1975 году, когда дельцы от плагиата не располагали и тысячной долей сегодняшних возможностей, как технических, так и социально-экономических.
Два аспекта проблемы достоверности информации действуют синхронно, в сочетании друг с другом. Их соотнесение может быть представлено, на наш взгляд, в виде логического квадрата, который мы предлагаем именовать матрицей достоверности (Рис. 1), где по горизонтали информация разделяется на качественную и некачественную, а по вертикали – на полученную, соответственно, честным и нечестным путём (фальсифицированное авторство, плагиат). В итоге часть информации квалифицируется как достоверная (Д), а часть – как недостоверная (Н).
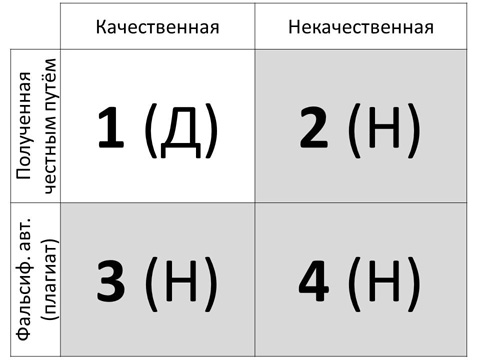
Рис. 1. Матрица достоверности информации, используемой в исследованиях
Согласно данной матрице, только одна из четырёх ячеек логического квадрата соотносится с достоверной информацией – ячейка (1). Остальные три соответствуют информации, либо полученной без помощи плагиата, но фактически неверной (2), либо, напротив, вполне соответствующей действительности, но «чужого» авторства (3), либо такому же плагиату, но ещё и ложному по содержанию (4).
В качестве средства нейтрализации категорий (3) и (4) можно было бы увидеть программные инструменты и специализированные сайты, посвящённые антиплагиату. Да, с одной стороны, существуют достаточно эффективные способы автоматизированного обнаружения плагиата. С другой, без достаточной квалификации преподавателя, без человеческого фактора – можно обойти любые заслоны. Да и эффективными эти программные средства оказываются обычно только на уровне учебно-научных работ – курсовых и дипломных. Более высокий уровень – диссертаций – предполагает высокую степень «защиты от защиты», работа по сути является оригинальной, плагиат же состоит в том, что пишет её один человек (или коллектив авторов), а публично выдаёт за свою – другой. Тем самым этот другой принимает на себя публичную ответственность за содержание «своей» диссертации, но, поскольку на самом деле он не владеет в должной мере этим содержанием, реальная научная ценность такой работы остаётся крайне низкой.
Что же касается категории (2), говоря об учебно-научных работах, есть смысл на уровне контроля со стороны преподавателя просто фильтровать используемые обучающимися источники информации. Проблема может быть вполне эффективно решена таким способом, и этого вполне достаточно.
На основании представленной выше матрицы достоверности мы предлагаем классификацию онлайн-источников (Таблица 1) с точки зрения целесообразности их использования в исследовательских работах различных уровней. Эта классификация не во всём совпадает с матрицей достоверности (Рис. 1), но в полной мере основана на ней.
Таблица 1. Классификация онлайн-источников по степени достоверности
|
№ |
Вид источника |
Оценка достоверности информации |
Группа достоверности по матрице (Рис. 1) |
|
1. |
Научные труды: монографии, изданные по решениям учёных советов, статьи из таким же образом легитимированных сборников, академические словари, энциклопедии, справочники, учебники и т. д. |
Достоверна |
1 |
|
2. |
Сайты практиков: личные и корпоративные сайты преподавателей и практикующих специалистов в конкретных областях. |
Скорее достоверна, чем нет |
1-2-3-4 |
|
3. |
Википедия и аналогичные ей источники, создаваемые на основе подхода Веб 2.0. |
Скорее недостоверна |
1-2-3-4 |
|
4. |
«Рефератные» сайты, предлагающие готовые работы (в том числе, на коммерческой основе). |
Недостоверна |
4 |
Таким образом, источники информации в Интернете, используемые в исследовательских работах (в том числе, учебных), мы предлагаем поделить на четыре категории. Материалы, отнесённые нами к категории (1), квалифицируются, как достоверные, их использование не нуждается в особых пояснениях, оно регламентировано в соответствующих нормативных документах. Информация, размещённая на авторских сайтах практиков (2), также, как правило, заслуживает доверия. Там сосредоточен и вербализирован личный опыт профессионалов в конкретной научной или практической области. Однако, такие сайты не всегда принадлежат достаточно квалифицированным авторам, информация не во всех случаях должным образом апробирована и верифицирована, плагиат и использование недостоверных источников здесь нельзя исключить в полной мере. Чем выше уровень научной работы, тем осторожнее следует её автору относиться к источникам этой группы. Материалы категории (3) из нашей таблицы формально могут быть отнесены к тем же ячейкам матрицы достоверности (Рис. 1), тем не менее, вероятность, что информация окажется недостоверной, здесь возрастает на порядок. Всё дело в ответственности, о которой мы уже говорили выше. Авторы Википедии анонимны, они ничем не рискуют (научной репутации у них зачастую просто нет, как таковой; нечем и рисковать), а стать автором может абсолютно любой пользователь Интернета, вне зависимости от образования, профессии, возраста и даже душевного здоровья. Поэтому материалы Википедии, особенно дефиниции, фактически не могут быть полноценно использованы в научной работе. Что же касается материалов Интернета, относимых к категории (4), они в качестве источников информации для научной работы не представляют абсолютно никакой ценности. По совокупности причин, изложенных выше в ходе нашего исследования.
Литература
1. October 2011 Web Server Survey. Сайт компании Netcraft. Режим доступа: http://news.netcraft.com/archives/2011/10/06/october-2011-web–server–survey.html
2. Shannon C.E. A Mathematical Theory of Communication // Bell System Technical Journal, 27, pp. 379–423 & 623–656, July & October, 1948.
3. Михалков С. В. Пена. Комедия нравов. Театр для детей. М., “Искусство”, 1977.